Главная » Бесплатные рефераты » Бесплатные рефераты по информатике »
Реляционные базы данных и СУБД
![Реляционные базы данных и СУБД [20.01.13]](/files/works_screen/1/33/50.png)
Тема: Реляционные базы данных и СУБД
Раздел: Бесплатные рефераты по информатике
Тип: Курсовая работа | Размер: 110.96K | Скачано: 523 | Добавлен 20.01.13 в 23:47 | Рейтинг: 0 | Еще Курсовые работы
Вуз: ВЗФЭИ
Год и город: Москва 2012
СОДЕРЖАНИЕ
Введение 3
Глава 1. Основные понятия БД и СУБД 4
1.1 Данные и ЭВМ 4
1.2 Архитектура СУБД 6
1.3 Модели данных 9
Глава 2. Реляционный подход 11
2.1 Реляционная структура данных 11
2.2 Реляционная база данных 14
2.3 Манипулирование реляционными данными 17
Заключение 19
Практическая часть 22
Список использованной литературы 26
ВВЕДЕНИЕ.
Основные идеи современной информационной технологии базируются на концепции баз данных (БД). Согласно данной концепции основой информационной технологии являются данные, организованные в БД, адекватно отражающие реалии действительности в той или иной предметной области и обеспечивающие пользователя актуальной информацией в соответствующей предметной области. В широком смысле слова база данных — это совокупность описаний объектов реального мира и связей между ними, актуальных для конкретной прикладной области.
Как сущности, атрибуты и связи отображаются на структуры данных - определяется моделью данных.
Традиционно все СУБД классифицируются в зависимости от модели данных, которая лежит в их основе. Принято выделять иерархическую, сетевую и реляционную модели данных. Иногда к ним добавляют модель данных на основе инвертированных списков. Соответственно говорят об иерархических, сетевых, реляционных СУБД или о СУБД на базе инвертированных списков.
По распространенности и популярности реляционные СУБД сегодня — вне конкуренции. Они стали фактическим промышленным стандартом, и поэтому отечественному пользователю придется столкнуться в своей практике именно с реляционной СУБД.
Основы реляционной модели данных были впервые изложены в статье Е.Кодда в 1970 г. Эта работа послужила стимулом для большого количества статей и книг, в которых реляционная модель получила дальнейшее развитие. Наиболее распространенная трактовка реляционной модели данных принадлежит К.Дейту. Согласно Дейту, реляционная модель состоит из трех частей:
Структурной части.
Целостной части.
Манипуляционной части.
Структурная часть описывает, какие объекты рассматриваются реляционной моделью. Постулируется, что единственной структурой данных, используемой в реляционной модели, являются нормализованные n-арные отношения. Целостная часть описывает ограничения специального вида, которые должны выполняться для любых отношений в любых реляционных базах данных. Это целостность сущностей и целостность внешних ключей. Манипуляционная часть описывает два эквивалентных способа манипулирования реляционными данными - реляционную алгебру и реляционное исчисление.
Цель данной работы рассмотреть структурную и целостную часть реляционной модели базы данных.
Глава 1. Основные понятия БД и СУБД
1.1 Данные и ЭВМ
Восприятие реального мира можно соотнести с последовательностью разных, хотя иногда и взаимосвязанных, явлений. С давних времен люди пытались описать эти явления (даже тогда, когда не могли их понять). Такое описание называют данными.
Традиционно фиксация данных осуществляется с помощью конкретного средства общения (например, с помощью естественного языка или изображений) на конкретном носителе (например, камне или бумаге). Обычно данные (факты, явления, события, идеи или предметы) и их интерпретация (семантика) фиксируются совместно, так как естественный язык достаточно гибок для представления того и другого. Примером может служить утверждение "Стоимость авиабилета 128". Здесь "128" – данное, а "Стоимость авиабилета" – его семантика.
Нередко данные и интерпретация разделены. Например, "Расписание движения самолетов" может быть представлено в виде таблицы , в верхней части которой (отдельно от данных) приводится их интерпретация. Такое разделение затрудняет работу с данными (трудно быстро получить сведения из нижней части таблицы).
Применение ЭВМ для ведения и обработки данных обычно приводит к еще большему разделению данных и интерпретации. ЭВМ имеет дело главным образом с данными как таковыми. Большая часть интерпретирующей информации вообще не фиксируется в явной форме (ЭВМ не "знает", является ли "21.50" стоимостью авиабилета или временем вылета). Почему же это произошло?
Существует по крайней мере две исторические причины, по которым применение ЭВМ привело к отделению данных от интерпретации. Во-первых, ЭВМ не обладали достаточными возможностями для обработки текстов на естественном языке – основном языке интерпретации данных. Во-вторых, стоимость памяти ЭВМ была первоначально весьма велика. Память использовалась для хранения самих данных, а интерпретация традиционно возлагалась на пользователя. Пользователь закладывал интерпретацию данных в свою программу, которая "знала", например, что шестое вводимое значение связано с временем прибытия самолета, а четвертое – с временем его вылета. Это существенно повышало роль программы, так как вне интерпретации данные представляют собой не более чем совокупность битов на запоминающем устройстве.
Жесткая зависимость между данными и использующими их программами создает серьезные проблемы в ведении данных и делает использования их менее гибкими.
Нередки случаи, когда пользователи одной и той же ЭВМ создают и используют в своих программах разные наборы данных, содержащие сходную информацию. Иногда это связано с тем, что пользователь не знает (либо не захотел узнать), что в соседней комнате или за соседним столом сидит сотрудник, который уже давно ввел в ЭВМ нужные данные. Чаще потому, что при совместном использовании одних и тех же данных возникает масса проблем.
Разработчики прикладных программ (написанных, например, на Бейсике, Паскале или Си) размещают нужные им данные в файлах, организуя их наиболее удобным для себя образом. При этом одни и те же данные могут иметь в разных приложениях совершенно разную организацию (разную последовательность размещения в записи, разные форматы одних и тех же полей и т.п.). Обобществить такие данные чрезвычайно трудно: например, любое изменение структуры записи файла, производимое одним из разработчиков, приводит к необходимости изменения другими разработчиками тех программ, которые используют записи этого файла.
1.2 Архитектура СУБД
СУБД должна предоставлять доступ к данным любым пользователям, включая и тех, которые практически не имеют и (или) не хотят иметь представления о:
- физическом размещении в памяти данных и их описаний;
- механизмах поиска запрашиваемых данных;
- проблемах, возникающих при одновременном запросе одних и тех же данных многими пользователями (прикладными программами);
- способах обеспечения защиты данных от некорректных обновлений и (или) несанкционированного доступа;
- поддержании баз данных в актуальном состоянии
и множестве других функций СУБД.
При выполнении основных из этих функций СУБД должна использовать различные описания данных. А как создавать эти описания?
Естественно, что проект базы данных надо начинать с анализа предметной области и выявления требований к ней отдельных пользователей (сотрудников организации, для которых создается база данных). Подробнее этот процесс будет рассмотрен ниже, а здесь отметим, что проектирование обычно поручается человеку (группе лиц) – администратору базы данных (АБД). Им может быть как специально выделенный сотрудник организации, так и будущий пользователь базы данных, достаточно хорошо знакомый с машинной обработкой данных.
Объединяя частные представления о содержимом базы данных, полученные в результате опроса пользователей, и свои представления о данных, которые могут потребоваться в будущих приложениях, АБД сначала создает обобщенное неформальное описание создаваемой базы данных. Это описание, выполненное с использованием естественного языка, математических формул, таблиц, графиков и других средств, понятных всем людям, работающих над проектированием базы данных, называют инфологической моделью данных (рис. 1).
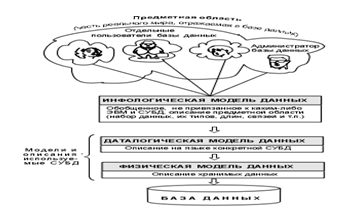
Такая человеко-ориентированная модель полностью независима от физических параметров среды хранения данных. В конце концов этой средой может быть память человека, а не ЭВМ. Поэтому инфологическая модель не должна изменяться до тех пор, пока какие-то изменения в реальном мире не потребуют изменения в ней некоторого определения, чтобы эта модель продолжала отражать предметную область.
Остальные модели, показанные на рис. 1, являются компьютеро-ориентированными. С их помощью СУБД дает возможность программам и пользователям осуществлять доступ к хранимым данным лишь по их именам, не заботясь о физическом расположении этих данных. Нужные данные отыскиваются СУБД на внешних запоминающих устройствах по физической модели данных.
Так как указанный доступ осуществляется с помощью конкретной СУБД, то модели должны быть описаны на языке описания данных этой СУБД. Такое описание, создаваемое АБД по инфологической модели данных, называют даталогической моделью данных.
Трехуровневая архитектура (инфологический, даталогический и физический уровни) позволяет обеспечить независимость хранимых данных от использующих их программ. АБД может при необходимости переписать хранимые данные на другие носители информации и (или) реорганизовать их физическую структуру, изменив лишь физическую модель данных. АБД может подключить к системе любое число новых пользователей (новых приложений), дополнив, если надо, даталогическую модель. Указанные изменения физической и даталогической моделей не будут замечены существующими пользователями системы (окажутся "прозрачными" для них), так же как не будут замечены и новые пользователи. Следовательно, независимость данных обеспечивает возможность развития системы баз данных без разрушения существующих приложений.
1.3Модели данных
Инфологическая модель отображает реальный мир в некоторые понятные человеку концепции, полностью независимые от параметров среды хранения данных. Существует множество подходов к построению таких моделей: графовые модели, семантические сети, модель "сущность-связь" и т.д. Наиболее популярной из них оказалась модель "сущность-связь".
Инфологическая модель должна быть отображена в компьютеро-ориентированную даталогическую модель, "понятную" СУБД. В процессе развития теории и практического использования баз данных, а также средств вычислительной техники создавались СУБД, поддерживающие различные даталогические модели.
Сначала стали использовать иерархические даталогические модели. Простота организации, наличие заранее заданных связей между сущностями, сходство с физическими моделями данных позволяли добиваться приемлемой производительности иерархических СУБД на медленных ЭВМ с весьма ограниченными объемами памяти. Но, если данные не имели древовидной структуры, то возникала масса сложностей при построении иерархической модели и желании добиться нужной производительности.
Сетевые модели также создавались для мало ресурсных ЭВМ. Это достаточно сложные структуры, состоящие из "наборов" – поименованных двухуровневых деревьев. "Наборы" соединяются с помощью "записей-связок", образуя цепочки и т.д. При разработке сетевых моделей было выдумано множество "маленьких хитростей", позволяющих увеличить производительность СУБД, но существенно усложнивших последние. Прикладной программист должен знать массу терминов, изучить несколько внутренних языков СУБД, детально представлять логическую структуру базы данных для осуществления навигации среди различных экземпляров, наборов, записей и т.п. Один из разработчиков операционной системы UNIX сказал "Сетевая база – это самый верный способ потерять данные".
Сложность практического использования иерархических и сетевых СУБД заставляла искать иные способы представления данных. В конце 60-х годов появились СУБД на основе инвертированных файлов, отличающиеся простотой организации и наличием весьма удобных языков манипулирования данными. Однако такие СУБД обладают рядом ограничений на количество файлов для хранения данных, количество связей между ними, длину записи и количество ее полей.
Физическая организация данных оказывает основное влияние на эксплуатационные характеристики БД. Разработчики СУБД пытаются создать наиболее производительные физические модели данных, предлагая пользователям тот или иной инструментарий для поднастройки модели под конкретную БД. Разнообразие способов корректировки физических моделей современных промышленных СУБД не позволяет рассмотреть их в этом разделе.
Глава 2. Реляционный подход.
2.1 Реляционная структура данных
В конце 60-х годов появились работы, в которых обсуждались возможности применения различных табличных даталогических моделей данных, т.е. возможности использования привычных и естественных способов представления данных. Наиболее значительной из них была статья сотрудника фирмы IBM д-ра Э.Кодда (Codd E.F., A Relational Model of Data for Large Shared Data Banks. CACM 13: 6, June 1970), где, вероятно, впервые был применен термин "реляционная модель данных".
Будучи математиком по образованию Э.Кодд предложил использовать для обработки данных аппарат теории множеств (объединение, пересечение, разность, декартово произведение). Он показал, что любое представление данных сводится к совокупности двумерных таблиц особого вида, известного в математике как отношение – relation (англ.).
Наименьшая единица данных реляционной модели – это отдельное атомарное (неразложимое) для данной модели значение данных. Так, в одной предметной области фамилия, имя и отчество могут рассматриваться как единое значение, а в другой – как три различных значения.
Доменом называется множество атомарных значений одного и того же типа. Смысл доменов состоит в следующем. Если значения двух атрибутов берутся из одного и того же домена, то, вероятно, имеют смысл сравнения, использующие эти два атрибута (например, для организации транзитного рейса можно дать запрос "Выдать рейсы, в которых время вылета из Москвы в Сочи больше времени прибытия из Архангельска в Москву"). Если же значения двух атрибутов берутся из различных доменов, то их сравнение, вероятно, лишено смысла: стоит ли сравнивать номер рейса со стоимостью билета? Отношение на доменах D1, D2, ..., Dn (не обязательно, чтобы все они были различны) состоит из заголовка и тела. На рис. 3 приведен пример отношения для расписания движения самолетов.
Заголовок состоит из такого фиксированного множества атрибутов A1, A2, ..., An, что существует взаимно однозначное соответствие между этими атрибутами Ai и определяющими их доменами Di (i=1,2,...,n).
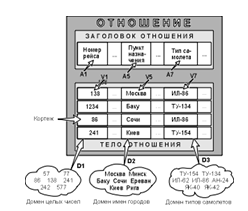
Рисунок 3. Отношение с математической точки зрения (Ai - атрибуты, Vi - значения атрибутов)
Тело состоит из меняющегося во времени множества кортежей, где каждый кортеж состоит в свою очередь из множества пар атрибут-значение (Ai:Vi), (i=1,2,...,n), по одной такой паре для каждого атрибута Ai в заголовке. Для любой заданной пары атрибут-значение (Ai:Vi) Vi является значением из единственного домена Di, который связан с атрибутом Ai.
Степень отношения – это число его атрибутов. Отношение степени один называют унарным, степени два – бинарным, степени три – тернарным, ..., а степени n – n-арным.
Кардинальное число или мощность отношения – это число его кортежей. Кардинальное число отношения изменяется во времени в отличие от его степени.
Поскольку отношение – это множество, а множества по определению не содержат совпадающих элементов, то никакие два кортежа отношения не могут быть дубликатами друг друга в любой произвольно-заданный момент времени. Пусть R – отношение с атрибутами A1, A2, ..., An. Говорят, что множество атрибутов K=(Ai, Aj, ..., Ak) отношения R является возможным ключом R тогда и только тогда, когда удовлетворяются два независимых от времени условия:
- Уникальность: в произвольный заданный момент времени никакие два различных кортежа R не имеют одного и того же значения для Ai, Aj, ..., Ak.
- Минимальность: ни один из атрибутов Ai, Aj, ..., Ak не может быть исключен из K без нарушения уникальности.
Каждое отношение обладает хотя бы одним возможным ключом, поскольку по меньшей мере комбинация всех его атрибутов удовлетворяет условию уникальности. Один из возможных ключей (выбранный произвольным образом) принимается за его первичный ключ. Остальные возможные ключи, если они есть, называются альтернативными ключами.
Вышеупомянутые и некоторые другие математические понятия явились теоретической базой для создания реляционных СУБД, разработки соответствующих языковых средств и программных систем, обеспечивающих их высокую производительность, и создания основ теории проектирования баз данных. Однако для массового пользователя реляционных СУБД можно с успехом использовать неформальные эквиваленты этих понятий:
Отношение – Таблица (иногда Файл),
Кортеж – Строка (иногда Запись),
Атрибут – Столбец, Поле.
2.2 Реляционная база данных
Реляционная база данных – это совокупность отношений, содержащих всю информацию, которая должна храниться в БД. Однако пользователи могут воспринимать такую базу данных как совокупность таблиц.
1. Каждая таблица состоит из однотипных строк и имеет уникальное имя.
2. Строки имеют фиксированное число полей (столбцов) и значений (множественные поля и повторяющиеся группы недопустимы). Иначе говоря, в каждой позиции таотличаются друг от друга хотя бы единственным значением, что позблицы на пересечении строки и столбца всегда имеется в точности одно значение или ничего.
3. Строки таблицы обязательно воляет однозначно идентифицировать любую строку такой таблицы.
4. Столбцам таблицы однозначно присваиваются имена, и в каждом из них размещаются однородные значения данных (даты, фамилии, целые числа или денежные суммы).
5. Полное информационное содержание базы данных представляется в виде явных значений данных и такой метод представления является единственным. В частности, не существует каких-либо специальных "связей" или указателей, соединяющих одну таблицу с другой. Так, связи между строкой с БЛ = 2 таблицы "Блюда" на рис. 4 и строкой с ПР = 7 таблицы продукты (для приготовления Харчо нужен Рис), представляется не с помощью указателей, а благодаря существованию в таблице "Состав" строки, в которой номер блюда равен 2, а номер продукта – 7.
6. При выполнении операций с таблицей ее строки и столбцы можно обрабатывать в любом порядке безотносительно к их информационному содержанию. Этому способствует наличие имен таблиц и их столбцов, а также возможность выделения любой их строки или любого набора строк с указанными признаками.
|
Блюда
Расход
|
Продукты
|
Состав
|
||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
Поставщики
|
Поставки
|
|||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
Рисунок 4.База данных "Питание" .
2.3 Манипулирование реляционными данными
Стремление к минимизации числа таблиц для хранения данных может привести к возникновению различных проблем при их обновлении и будут даны рекомендации по разбиению некоторых больших таблиц на несколько маленьких. Но как сформировать требуемый ответ, если нужные для него данные хранятся в разных таблицах?
Предложив реляционную модель данных, Э.Ф.Кодд создал и инструмент для удобной работы с отношениями – реляционную алгебру. Каждая операция этой алгебры использует одну или несколько таблиц (отношений) в качестве ее операндов и продуцирует в результате новую таблицу, т.е. позволяет "разрезать" или "склеивать" таблицы (рис. 5).
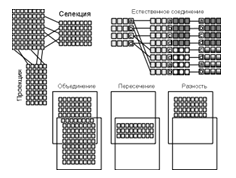
Рисунок 5. Некоторые операции реляционной алгебры
Созданы языки манипулирования данными, позволяющие реализовать все операции реляционной алгебры и практически любые их сочетания. Среди них наиболее распространены SQL (Structured Query Language – структуризованный язык запросов) и QBE (Quere-By-Example – запросы по образцу) . Оба относятся к языкам очень высокого уровня, с помощью которых пользователь указывает, какие данные необходимо получить, не уточняя процедуру их получения.
Заключение
В заключении необходимо сделать основные выводы по работе.
Реляционная модель данных состоит из трех частей:
Структурной части.
Целостной части.
Манипуляционной части.
В классической реляционной модели используются только простые (атомарные) типы данных. Простые типы данных не обладают внутренней структурой.
Домены - это типы данных, имеющие некоторый смысл (семантику). Домены ограничивают сравнения - некорректно, хотя и возможно, сравнивать значения из различных доменов.
Отношение состоит из двух частей - заголовка отношения и тела отношения. Заголовок отношения - это аналог заголовка таблицы. Заголовок отношения состоит из атрибутов. Количество атрибутов называется степенью отношения. Тело отношения - это аналог тела таблицы. Тело отношения состоит из кортежей. Кортеж отношения является аналогом строки таблицы. Количество кортежей отношения называется мощностью отношения.
Отношение обладает следующими свойствами:
В отношении нет одинаковых кортежей.
Кортежи не упорядочены (сверху вниз).
Атрибуты не упорядочены (слева направо).
Все значения атрибутов атомарны.
Реляционной базой данных называется набор отношений.
Схемой реляционной базы данных называется набор заголовков отношений, входящих в базу данных.
Отношение находится в Первой Нормальной Форме (1НФ), если оно содержит только скалярные (атомарные) значения.
Современные СУБД допускают использование null-значений, т.к. данные часто бывают неполными или неизвестными.
Средством, позволяющим однозначно идентифицировать кортежи отношения, являются потенциальные ключи отношения.
Потенциальный ключ отношения - это набор атрибутов отношения, обладающий свойствами уникальности и неизбыточности. Доступ к конкретному кортежу можно получить, лишь зная значение потенциального ключа для этого кортежа.
Традиционно один из потенциальных ключей объявляется первичным ключом, остальные - альтернативными ключами.
Потенциальный ключ, состоящий из одного атрибута, называется простым. Потенциальный ключ, состоящий из нескольких атрибутов, называется составным.
Отношения связываются друг с другом при помощи внешних ключей.
Внешний ключ отношения - это набор атрибутов отношения, содержащий ссылки на потенциальный ключ другого (или того же самого) отношения. Отношение, содержащее потенциальный ключ, на который ссылается некоторый внешний ключ, называется родительским отношением. Отношение, содержащее внешний ключ, называется дочерним отношением.
Внешний ключ не обязан обладать свойством уникальности. Поэтому, одному кортежу родительского отношения может соответствовать несколько кортежей дочернего отношения. Такой тип связи между отношениями называется "один-ко-многим". Связи типа "много-ко-многим" реализуются использованием нескольких отношений типа "один-ко-многим".
В любой реляционной базе данных должны выполняться два ограничения:
Целостность сущностей
Целостность внешних ключей
Правило целостности сущностей состоит в том, что атрибуты, входящие в состав некоторого потенциального ключа не могут принимать null-значений.
Правило целостности внешних ключей состоит в том, что внешние ключи не должны ссылаться на отсутствующие в родительском отношении кортежи, т.е. внешние ключи должны быть корректны.
Ссылочную целостность могут нарушить операции, изменяющие состояние базы данных. Такими операциями являются операции вставки, обновления и удаления кортежей.
Для поддержания ссылочной целостности обычно используются две основные стратегии:
RESTRICT (ОГРАНИЧИТЬ) - не разрешать выполнение операции, приводящей к нарушению ссылочной целостности.
CASCADE (КАСКАДИРОВАТЬ) - разрешить выполнение требуемой операции, но внести каскадные изменения в другие отношения так, чтобы не допустить нарушения ссылочной целостности.
Дополнительными стратегиями поддержания ссылочной целостности являются:
SET NULL (УСТАНОВИТЬ В NULL) - все некорректные значения внешних ключей изменять на null-значения.
SET DEFAULT (УСТАНОВИТЬ ПО УМОЛЧАНИЮ) - все некорректные значения внешних ключей изменять на некоторое значение, принятое по умолчанию.
В реальных СУБД можно также отказаться от использования какой-либо стратегии поддержания ссылочной целостности:
IGNORE (ИГНОРИРОВАТЬ) - выполнять операции, не обращая внимания на нарушения ссылочной целостности.
Пользователь может разработать свою уникальную стратегию поддержания ссылочной целостности.
Практическая часть.
Компания «Страхование» осуществляет страховую деятельность на территории России по видам полисов, представленных на рис. 3.1. Каждый полис имеет фиксированную цену.
Компания имеет свои филиалы в нескольких городах (рис. 3.2) и поощряет развитие каждого филиала, предоставляя определенный дисконт. Дисконт пересматривается ежемесячно по итогам общих сумм договоров по филиалам.
В конце каждого месяца составляется общий реестр договоров по всем филиалам (рис. 3.3).
Для решения задачи необходимо следующее.
1. Построить таблицы (рис. 3.1, 3.2, 3.3).
2. Организовать межтабличные связи для автоматического заполнения документа “Реестр договоров” при помощи функций ВПР или ПРОСМОТР (рис. 3.3.).
3. Произвести расчет суммы полисов по филиалам.
4. Построить и проанализировать графический отчет по полученным результатам.
|
Код вида страхового полиса |
Наименование страхового полиса |
Сумма страхового полиса, руб. |
|
101 |
От несчастного случая |
20 000 |
|
102 |
От автокатастрофы |
60 000 |
|
103 |
От авиакатастрофы |
50 000 |
|
104 |
Медицинский |
30 000 |
|
105 |
Автомобильный |
90 000 |
|
106 |
Жилищный |
700 000 |
Рис. 3.1. Виды страховых полисов
|
Код филиала |
Наименование филиала |
Дисконтный % с каждого полиса по филиалу |
|
100 |
Московский |
3 |
|
200 |
Тульский |
2 |
|
300 |
Уфимский |
1 |
|
400 |
Липецкий |
2 |
|
500 |
Ростовский |
3 |
|
600 |
Воронежский |
2 |
Рис. 3.2. Список филиалов компании «Страховщик»
|
Код филиала |
Наименование филиала |
Код стра-хового по-лиса |
Наименование полиса |
Дата выда-чи полиса |
Сумма полиса, руб. |
Сумма скидки по дисконту, руб. |
|
|
100 |
|
101 |
|
11.11.10 |
|
|
|
|
300 |
|
103 |
|
12.11.10 |
|
|
|
|
200 |
|
105 |
|
13.11.10 |
|
|
|
|
400 |
|
102 |
|
14.11.10 |
|
|
|
|
600 |
|
106 |
|
11.11.10 |
|
|
|
|
500 |
|
102 |
|
16.11.10 |
|
|
|
|
200 |
|
105 |
|
17.11.10 |
|
|
|
|
300 |
|
104 |
|
12.11.10 |
|
|
|
|
300 |
|
102 |
|
19.11.10 |
|
|
|
|
500 |
|
101 |
|
20.11.10 |
|
|
|
Рис. 3.3. Табличные данные реестра договоров
Описание алгоритма решения задачи.
- Запустить табличный процессор MS Excel.
- Создать книгу с именем «Страховщик».
- Лист 1 переименовать в лист с названием «Страховые полисы».
- На рабочем столе «страховые полисы» MS Excel создать таблицу видов страховых полюсов.
- Заполнить таблицу видов страховых полюсов исходными данными Лист 2 переименовать в лист с названием Страховщик.
- На рабочем листеСтраховщик MS Excel создать таблицу, в которой будет содержаться список филиалов.
- Заполнить таблицу со списком филиалов исходными данными
- Разработать структуру шаблона таблицы «Реестр договоров»
|
Колонка электронной таблицы |
Наименование (реквизит) |
Тип данных |
|
A |
Код филиала |
числовой |
|
B |
Наименование филиала |
текстовый |
|
C |
Код страхового полиса |
числовой |
|
D |
Наименование полиса |
текстовый |
|
E |
Дата выдачи полиса |
дата |
|
F |
Сумма полиса, руб. |
числовой |
|
G |
Сумма скидки по дисконту, руб. |
числовой |
- Лист 3 переименовать в лист с названием Список филиалов MS Excel.
- На рабочем листеСписок филиалов MS Excel создать таблицу, в которой будет содержаться список филиалов компании «Страховщик».
- Заполнить таблицу «Список филиалов компании «Страховщик» исходными данными Заполнить графу Наименование филиала таблицы «Список филиалов компании «Страховщик», находящейся на листе Список филиалов следующим образом:
- Занести в ячейку F2 формулу и размножить её для остальных ячеек данной графы (с В2 по В16).
- Заполнить графу Сумма полиса, руб. таблицы Реестр договоров следующим образом: занести в ячейку F3 формулу и размножить её для остальных ячеек данной графы (с F3 по F16).
- В таблице Реестр договоров вставить автоматические промежуточные (для каждого филиала) и общие итоги в списке Наименование полиса
|
Код филиала |
Наименование филиала |
Код стра-хового по-лиса |
Наименование полиса |
Дата выда-чи полиса |
Сумма полиса, руб. |
Сумма скидки по дисконту, руб. |
Итог |
|
100 |
Московский |
101 |
От несчастного случая |
11.11.2010 |
20000 |
600 |
19400 |
|
300 |
Уфимский |
103 |
От авиакатастрофы |
12.11.2010 |
50000 |
500 |
49500 |
|
200 |
Тульский |
105 |
Автомобильный |
13.11.2010 |
90000 |
1800 |
88200 |
|
400 |
Липецкий |
102 |
От автокатастрофы |
14.11.2010 |
60000 |
1200 |
58800 |
|
600 |
Воронежский |
106 |
Жилищный |
11.11.2010 |
700000 |
14000 |
686000 |
|
500 |
Ростовский |
102 |
От автокатастрофы |
16.11.2010 |
60000 |
1800 |
58200 |
|
200 |
Тульский |
105 |
Автомобильный |
17.11.2010 |
90000 |
1800 |
88200 |
|
300 |
Уфимский |
104 |
Медицинский |
12.11.2010 |
30000 |
300 |
29700 |
|
300 |
Уфимский |
102 |
От автокатастрофы |
19.11.2010 |
60000 |
600 |
59400 |
|
500 |
Ростовский |
101 |
От несчастного случая |
20.11.2010 |
20000 |
600 |
19400 |
- Лист 4 переименовать в лист с названием График.
- На рабочем листе График MS Excel создать сводную таблицу. Путём межтабличных связей автоматически заполнить графы Наименование полиса, Сумма скидки по дисконту,руб. и Общий итог .
- Результаты вычислений представить графически. Построить гистограмму.
СПИСОК ИСПОЛЬЗОВАННОЙ ЛИТЕРАТУРЫ
- Дейт К. Руководство по реляционной СУБД DB2. - М.: Финансы и статистика, 1988. - 320 с.
- Кириллов В.В. Основы проектирования реляционных баз данных .Учебное пособие. - СПб.: ИТМО, 1994. - 90 с.
- Мейер М. Теория реляционных баз данных. -М.: Мир, 1987. - 608 с.
- Ульман Дж. Базы данных на Паскале. -М.: Машиностроение, 1990. - 386 с.
- http://www.citforum.ru/database/sql_kg/index.shtml “ Основы проектирования реляционных баз данных ”
- Агибалов А. В., Горюхина Е.Ю. Автоматизированные системы обработки экономической информации. Учебное пособие – 3-е изд., доп.: Воронеж.: ВГАУ, 2000.
- Диго С.М. Базы данных: проектирование и использование. Учебное пособие для вузов. – Москва.: Финансы и статистика, 2005.
- Информатика. Базовый курс /Симонович С.В. и др. - СПб: Издательство "Питер", 2006.
- Компьютерный практикум. Программирование в среде Турбо-Паскаль и СУБД типа Fox. Методические указания к выполнению курсового проекта. /Сост.: О.Н. Леонова, И.А. Несмеянов; ГАУ, М., 1998.
- Лемашко Е. В., Романчуков В.Г. Программирование в системе команд СУБД семейства Fox: учебное пособие/ ГАУ, М., 1998.
Внимание!
Если вам нужна помощь в написании работы, то рекомендуем обратиться к профессионалам. Более 70 000 авторов готовы помочь вам прямо сейчас. Бесплатные корректировки и доработки. Узнайте стоимость своей работы
 LediBoss
LediBoss Понравилось? Нажмите на кнопочку ниже. Вам не сложно, а нам приятно).
Чтобы скачать бесплатно Курсовые работы на максимальной скорости, зарегистрируйтесь или авторизуйтесь на сайте.
Важно! Все представленные Курсовые работы для бесплатного скачивания предназначены для составления плана или основы собственных научных трудов.
Друзья! У вас есть уникальная возможность помочь таким же студентам как и вы! Если наш сайт помог вам найти нужную работу, то вы, безусловно, понимаете как добавленная вами работа может облегчить труд другим.
Если Курсовая работа, по Вашему мнению, плохого качества, или эту работу Вы уже встречали, сообщите об этом нам.
Добавление отзыва к работе
Добавить отзыв могут только зарегистрированные пользователи.
Похожие работы
- Сетевые базы данных и СУБД
- Проектирование базы данных методом ER-моделирования
- Реляционные базы данных и СУБД
- Базы данных оптового склада
- Система управления базами данных MS ACCESS
- Настольные СУБД
- Базы данных, основные модели их организации
- Настольные системы управления базами данных
- Методы защиты данных в СУБД SQL Server
- Настольные системы управления базами данных
- Разработка базы данных для автоматизации фирмы
- Настольные СУБД
- Безопасность баз данных
- Создание списков и баз данных в среде MS Office